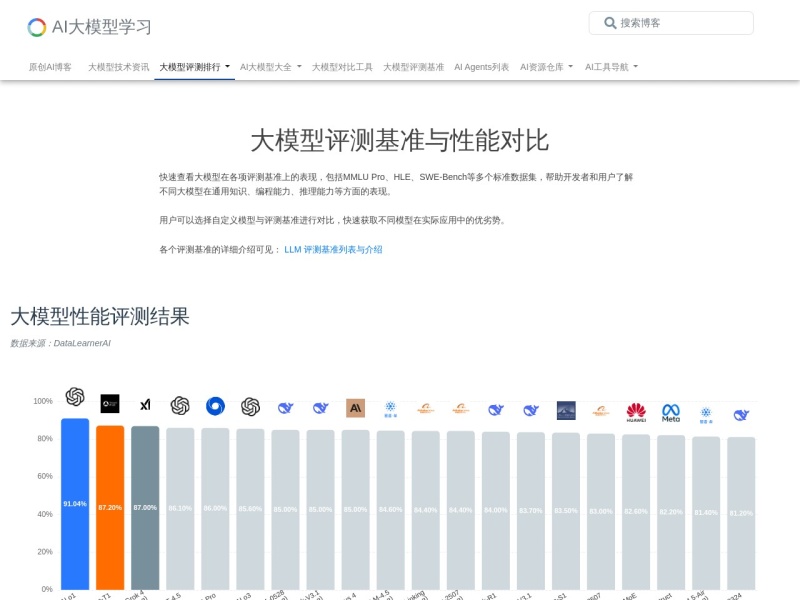
DataLearner AI大模型评测榜单是国内专注于AI大模型性能量化评估的专业平台,核心通过整合全球主流大模型在标准化基准数据集上的测试结果,为用户提供“多维度、可对比、透明化”的模型性能参考。平台覆盖OpenAI、谷歌DeepMind、腾讯、阿里、智谱AI等国内外140+款大模型,测试基准涵盖通用知识(MMLU Pro)、编程能力(SWE-bench Verified)、数学推理(MATH-500、AIME 2024)、代码生成(LiveCodeBench)等关键能力维度,同时标注模型参数规模与开源/商用授权情况,解决“模型众多、性能难辨、选型盲目”的痛点,是AI开发者、企业选型人员及研究者的核心参考工具。
聚焦关键能力维度:每个基准对应特定能力测试——MMLU Pro评估通用知识与跨领域理解(如OpenAI o1以91.04分居首)、SWE-bench Verified验证真实编程任务解决能力(Claude Opus 4以72.50分领先)、MATH-500与AIME 2024测试数学推理深度(Gemini-2.5-Pro MATH-500得98.80分)、LiveCodeBench衡量代码生成效率(Grok 4以82.00分最优),全面反映模型综合实力。
基准详情可查:提供“LLM评测基准列表与介绍”链接,帮助用户理解各基准测试逻辑(如数据来源、评分标准),避免仅看分数忽略能力适配性。
结构化呈现数据:表格包含“排名、模型、各基准得分、参数规模、开源/商用授权”5大核心信息,如排名Top3的OpenAI o1(不开源)、腾讯Hunyuan-T1(不开源)、xAI Grok 4(不开源),国内模型如DeepSeek-R1-0528(6710亿参数,免费商用)、智谱GLM-4.5(3550亿参数,免费商用)均清晰标注关键属性。
支持筛选与定位:用户可快速定位目标模型(如阿里Qwen系列、华为盘古系列),对比同参数规模或同授权类型模型的性能差异(如Meta Llama 4系列不同版本的MMLU Pro得分差距)。
开发者模型选型:开发编程类应用时,参考SWE-bench Verified与LiveCodeBench得分,优先选择Claude Opus 4(72.50分)、Grok 4(58.60分)等编程能力突出的模型;若需免费商用,可选择DeepSeek-R1-0528(57.60分)。
科研人员性能对比:研究“模型参数与能力相关性”时,通过表格筛选不同参数规模模型(如300亿-7000亿参数),对比其MMLU Pro得分变化,辅助学术分析。
企业技术决策:企业采购大模型服务时,结合“开源情况”与“关键能力得分”——若需本地化部署,选择免费商用的智谱GLM-4.5或阿里Qwen3系列;若追求极致性能,可考虑不开源的OpenAI o1或Gemini-2.5-Pro。
普通用户认知参考:想了解“哪个模型数学最好”时,查看MATH-500榜单,Gemini-2.5-Pro(98.80分)、OpenAI o3(98.10分)等模型表现直观可见。
AI开发者/工程师:需根据业务场景(如编程、数学推理)选择适配模型的技术人员。
科研与教育工作者:从事LLM领域研究,需量化对比模型性能的学者与教师。
企业技术选型负责人:统筹大模型采购或部署,关注性能、成本与授权合规性的决策者。
AI大模型爱好者:希望了解全球模型发展水平与能力差异的普通用户。
数据全面且权威:覆盖140+款全球主流模型,测试基准均为行业公认标准(如MMLU Pro、SWE-bench),数据来源标注为DataLearnerAI,可信度高,避免非标准化测试的误导性。
信息维度实用:除得分外,重点标注“参数规模”与“开源/商用授权”,直击用户选型核心痛点(如中小企业关注免费商用、开发者关注参数与部署成本)。
操作门槛低:无需注册登录,网页端直接浏览;支持自定义对比,非专业用户也能快速获取关键结论,无需掌握复杂评测方法。
动态更新及时:跟踪全球大模型迭代(如OpenAI o系列、Gemini 2.5系列),及时更新榜单数据,确保参考价值时效性。

如果追光,那就成为光!

国内AI声音创作平台,核心提供“AI配音、语音识别、声音克隆、音视频翻译配音、音频处理”全流程服务,含1200+AI主播音色、110+支持语言、80+情感风格,语音识别准确率达95%,定位“个人与企业的‘AI声音创作搭档’”

抖音官方推出的平台治理与信任建设专属平台(当前处于试运行阶段),核心提供“规则公开、安全治理成果公示、问题解决方案、双向反馈渠道”四大服务,覆盖“用户-创作者-监管机构”全生态角色,定位“抖音生态内‘规则透明、安全可控、服务可及’的信任枢纽”

全球AI研究与创意技术平台,核心聚焦“基础AI模型研发(如Gen-4)、多模态世界模拟器构建、创意内容制作资助”,旗下Runway Studios负责影视、纪录片等内容生产,同时举办艺术活动探索科技与创造力的融合,定位“AI研究者、创意从业者、内容创作者的‘多模态技术与创意枢纽’”





